关键字:elasticsearch, logstash, kibana, filebeat
整体框架介绍
Elasticsearch
一个近乎实时查询的全文搜索引擎。Elasticsearch的设计目标就是要能够处理和搜索巨量的日志数据。Logstash
读取原始日志,并对其进行分析和过滤,然后将其转发给其他组件(比如Elasticsearch)进行索引或存储。Logstash支持丰富的Input和Output类型,能够处理各种应用的日志。Kibana
一个基于JavaScript的Web图形界面程序,专门用于可视化Elasticsearch的数据。Kibana能够查询Elasticsearch并通过丰富的图表展示结果。用户可以创建Dashboard来监控系统的日志。Filebeat
引入Filebeat作为日志搜集器,主要是为了解决Logstash开销大的问题。相比Logstash,Filebeat所占系统的CPU和内存几乎可以忽略不计。
Filebeat 日志数据采集,Logstash 过滤,Elasticsearch 存储,Kibana 展示
主要的架构图如下:

其中日志的收集过程,也就filebeat部分是安装在需要收集日志的机器上的(比如,你有一个console服务,需要收集这个服务的日志,就需要将filebeat安装到console机器上。
整个后面的这一部分,对于处理量不大的服务,可以直接使用现成的docker镜像sebp/elk,一是部署简单,而是集成度高,不需要过分关心后三者之间的通信,镜像内都给处理好了,镜像内提供的服务都是最基础的服务,也就是一些进阶需求可能没有包含进去,所以,我们也可以在现有的这个sebp/elk镜像的基础上,自己二次开发,运行新的容器来达到我们更高的需求的目的。
docker上镜像的地址:dockerhub elk
elk-docker doc地址:elk-docker
github上的开源项目:github/elk-docker
满足的需求
现在手头的项目有多个test环境和debug环境,同时部署了若干个服务,如果服务出现问题,可能需要去不同机器去排查,费时费力,需要一个集中管理平台,一旦需要查看日志,又可以开箱即用的web界面满足需求。
环境说明
环境说明
linux:Ubuntu 16.04docker:Docker version 18.09.5elk:sebp/elk latestfilebeat:filebeat-7.0.0
elk跟filebeat在不同一台机器上
安装与配置(主线):
filebeat的安装与配置
上面说过,filebeat是安装部署到需要收集服务的机器上的,然后配置好对应的输入与输出,就可以工作了,一般输入就是对应的需要收集的log文件的地址,而输出可以是logstash或者Elasticache(可以部署在本机的,也可以是部署在其他机器上的)。
安装
filebeat安装地址,点击对应页面
推荐使用deb或者rpm在Linux机器上安装
deb安装方式,直接在Ubuntu机器上运行如下命令即可
|
|
rpm安装方式。
|
|
Mac上的安装方式
|
|
服务的启动等操作
安装后,默认是由systemctl来管理的
|
|
查看服务的状态
|
|
配置
安装完filebeat并能够启动和查看状态之后,我们就需要对其进行基础的配置,来和我们的elk配合。
下面是一个最基础的配置信息,如果再有更高的需求,可以查阅对应的文档来修改:
配置文件的地址/etc/filebeat/filebeat.yml, 可能需要sudo权限, 详细的配置信息请参考这里。
|
|
基本上配置好了这个信息后,就可以重新启动服务了,重启后,如果elk那边运行时正常的,那么这边的日志会源源不断的扔到Elasticache或者logstash中去,kibana上就可以看到对应的日志信息了。
ELK的安装与配置
ELK是Logstash,Elasticsearch,Kibana的组合体,他们三个单独安装适用于大的集群,稍微中等或者小一点的服务,可以直接使用集成好的docker的elk镜像来安装。
总的介绍文档可以看这一篇
安装与配置
首先保证已经安装好了docker环境
由于elk比较消耗资源,因此需要令这个docker进程的虚拟内存大一些,我们需要首先修改max_map_count这个参数,这个参数的具体指的是:
max_map_count : 文件包含限制一个进程可以拥有的VMA(虚拟内存区域)的数量。虚拟内存区域是一个连续的虚拟地址空间区域。在进程的生命周期中,每当程序尝试在内存中映射文件,链接到共享内存段,或者分配堆空间的时候,这些区域将被创建。调优这个值将限制进程可拥有VMA的数量。限制一个进程拥有VMA的总数可能导致应用程序出错,因为当进程达到了VMA上线但又只能释放少量的内存给其他的内核进程使用时,操作系统会抛出内存不足的错误。如果你的操作系统在NORMAL区域仅占用少量的内存,那么调低这个值可以帮助释放内存给内核用。
需要运行如下的命令,调高vma的大小,不然会出现安装好elk之后,容器自动停止运行的现象, 即运行这个镜像至少需要262144的内存:
|
|
然后就是docker的一系列操作了
|
|
|
|
这一步会花点时间,耐心等待。
启动之后我们去配置对应的logstash信息。
|
|
将这个配置文件修改文如下, 即删除了SSL的配置信息,因为我们在filebeat中也没有使用SSL,因此这里必须将配置信息的东西关掉:
|
|
然后重启docker服务
|
|
此时已经基本完成了部署,为了提供可查看的kibana界面,我们需要配置一下NGINX地址
|
|
我们打开kibana的NGINX配置之后,就可以访问 http://nideyuming来访问kibana服务了。
kibana界面的一些设置
登陆对应的地址后,会看到一个kibana的界面。
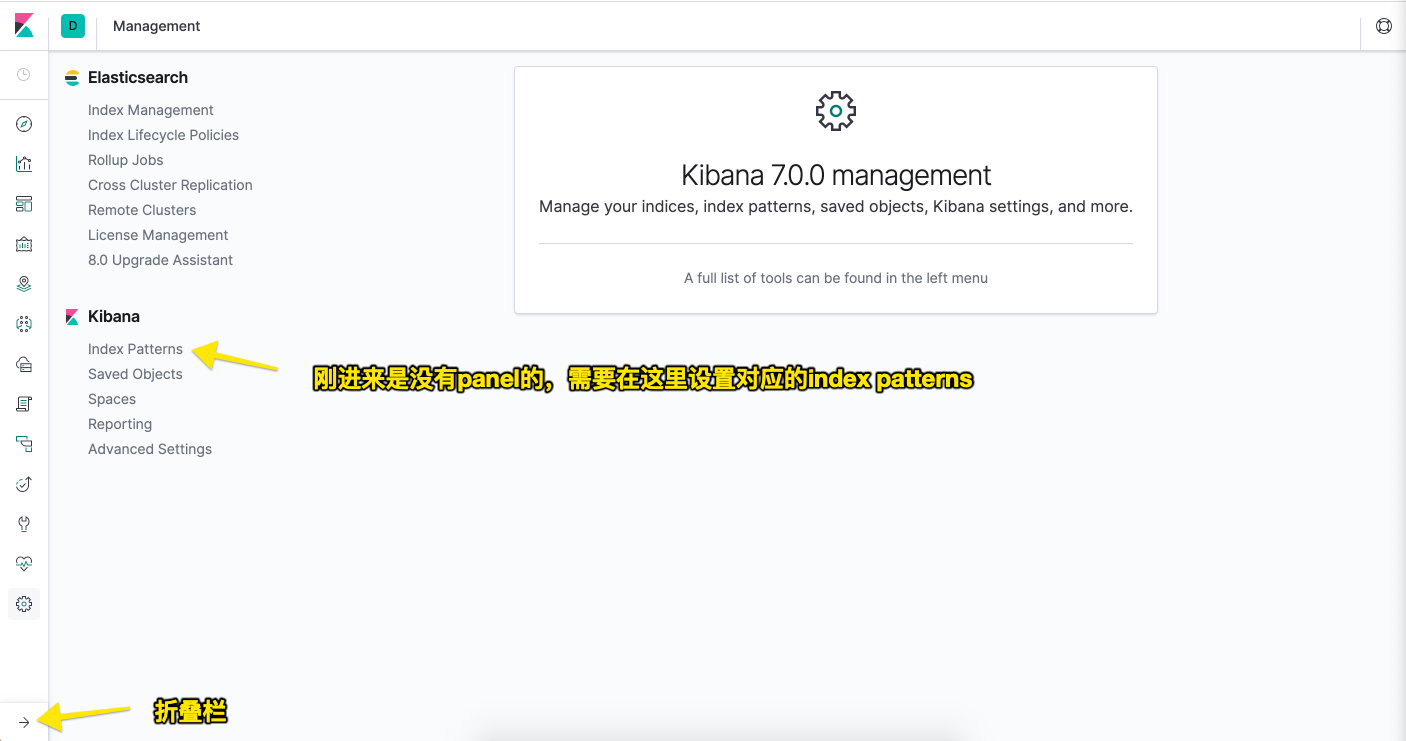
然后一步步的设置(具体的设置这里不想详细谈了,找其他的教程来看即可)

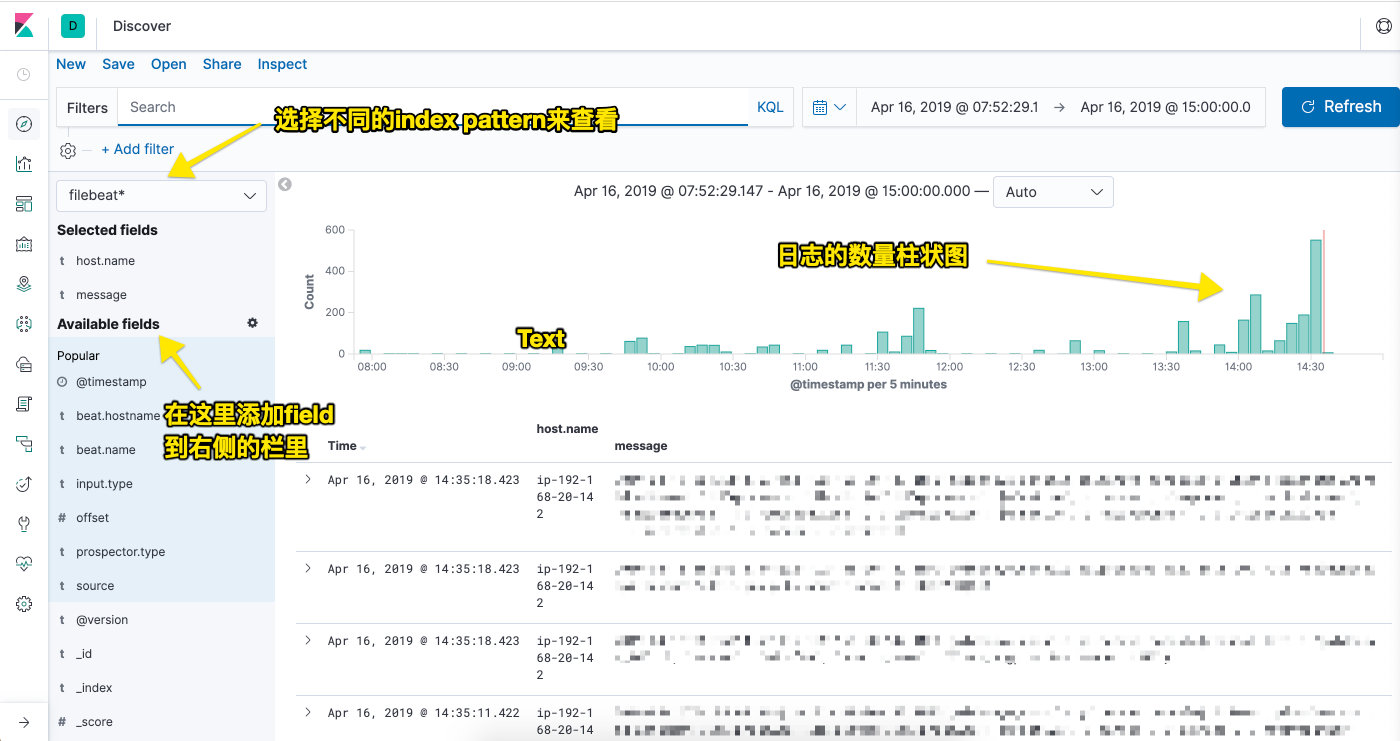
基本已经完成了主线的介绍,后面会在介绍一些非常主线的内容。
安装与配置(非主线)
关于SSL的一些东西
以下信息供选择性查看,关于logstash配置删除的内容的
将以下三行删除掉。这三行的意思是是否使用证书,本例是不使用证书的,如果你需要使用证书,将logstash.crt拷贝到客户端,然后在filebeat.yml里面添加路径即可
|
|
注意:sebp/elk docker是自建立了一个证书logstash.crt,默认使用*通配配符,如果你使用证书,filebeat.yml使用的服务器地址必须使用域名,不能使用IP地址,否则会报错
这里如果不去掉这三行配置的话,在后面启动filebeat时,会提示如下错误:
|
|
如何测试docker内的logstash是否正常工作
进入容器, 然后运行一下命令,然后可以查看对应的交互信息,或者直接看kibana的日志收集index-pattern有没有匹配的项目即可。
|
|
具体的logstash过滤filter机制如何进行
进入容器,修改如下的文件即可

如果想增加更多的配置文件,可以新建dockerfile自己制作镜像来使用,比如如下的内容
|
|
然后执行build等一系列操作生成我们新的镜像,然后就可以使用这个镜像,开启新的容器进行服务了。
参考文档
- Docker ELK+Filebeat安装与配置(推荐)
- elastic.io filebeat install
- 搭建ELK日志分析平台(下)—— 搭建kibana和logstash服务器(推荐)
- 搭建ELK日志分析平台(上)—— ELK介绍及搭建 Elasticsearch 分布式集群(推荐)
- Logstash Filebeat 安装配置之使用 Kibana 分析日志数据(推荐)
- 如何在 CentOS 7 上安装 Elastic Stack(推荐)
- https://www.elastic.co/guide/en/beats/filebeat/current/setup-repositories.html
- https://www.elastic.co/guide/en/beats/filebeat/current/config-filebeat-logstash.html
- https://www.elastic.co/guide/en/logstash/7.0/use-ingest-pipelines.html
- https://www.elastic.co/guide/en/elastic-stack-get-started/7.0/get-started-elastic-stack.html
- https://www.elastic.co/guide/en/logstash/7.0/logstash-config-for-filebeat-modules.html

