关键词:爬虫,拉勾网
这一节,我们讨论一下ajax加载且是POST方法的拉勾网如何爬取
先讲一下POST的用法——传递参数 data
通常,你想要发送一些编码为表单形式的数据——非常像一个 HTML 表单。要实现这个,只需简单地传递一个字典给 data 参数。你的数据字典在发出请求时会自动编码为表单形式
|
|
我们先去看拉勾网的页面

我们查看源码如下
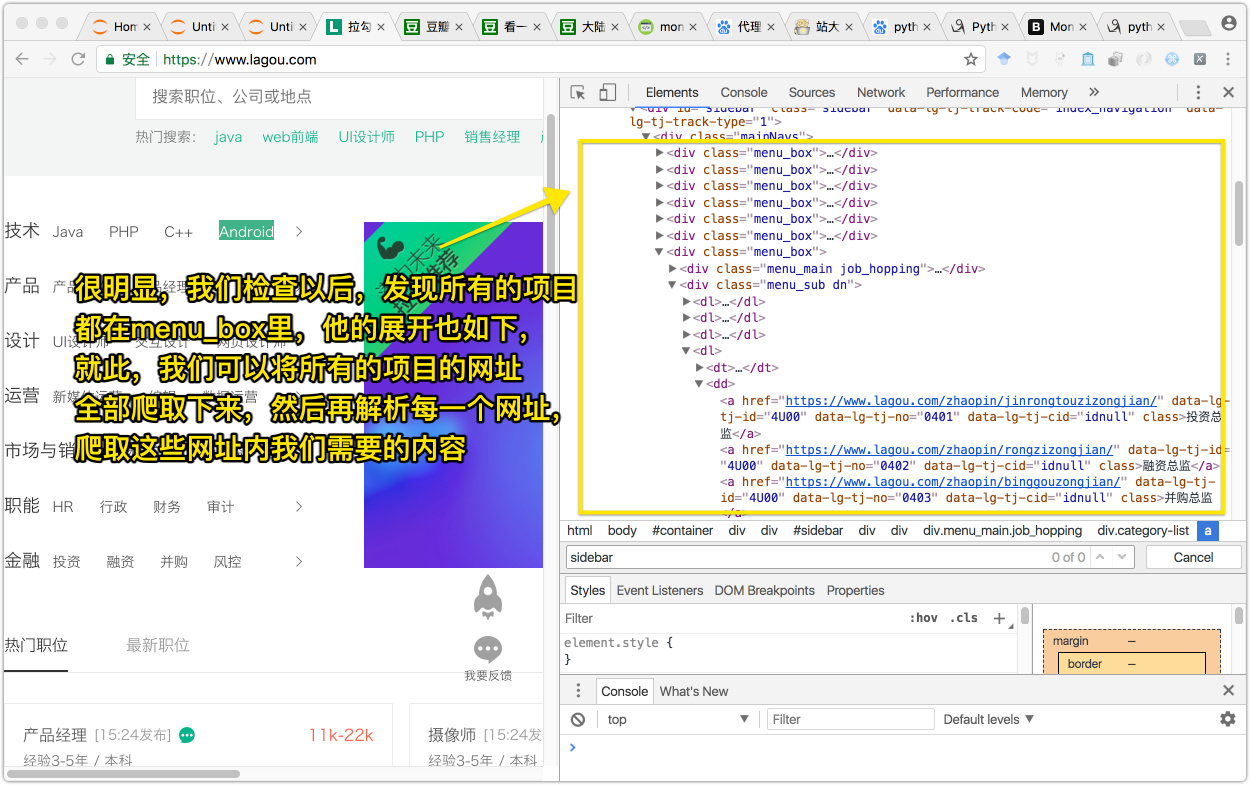
现在我们就可以根据源码,解析出大概的数据了,下面我讲一下爬取的思路
伪装浏览器
伪装浏览器我们使用fake_useragent库,其他的用法请看库的介绍
|
|
然后把它放到headers里就可以了
|
|
简单的IP池
首先找到一些免费的代理ip,然后,使用这些IP做一个简单的IP池
|
|
制作一个字典格式的proxies
|
|
放入requests请求即可
|
|
requests里的具体传入参数请查看库文档
解析主页的所有职位对应的URL
|
|
根据这些职位与对应的URL找到对应网页,并爬取想要的数据
|
|

